Relatório do Projeto de Machine Learning – KNN
1. Exploração dos Dados
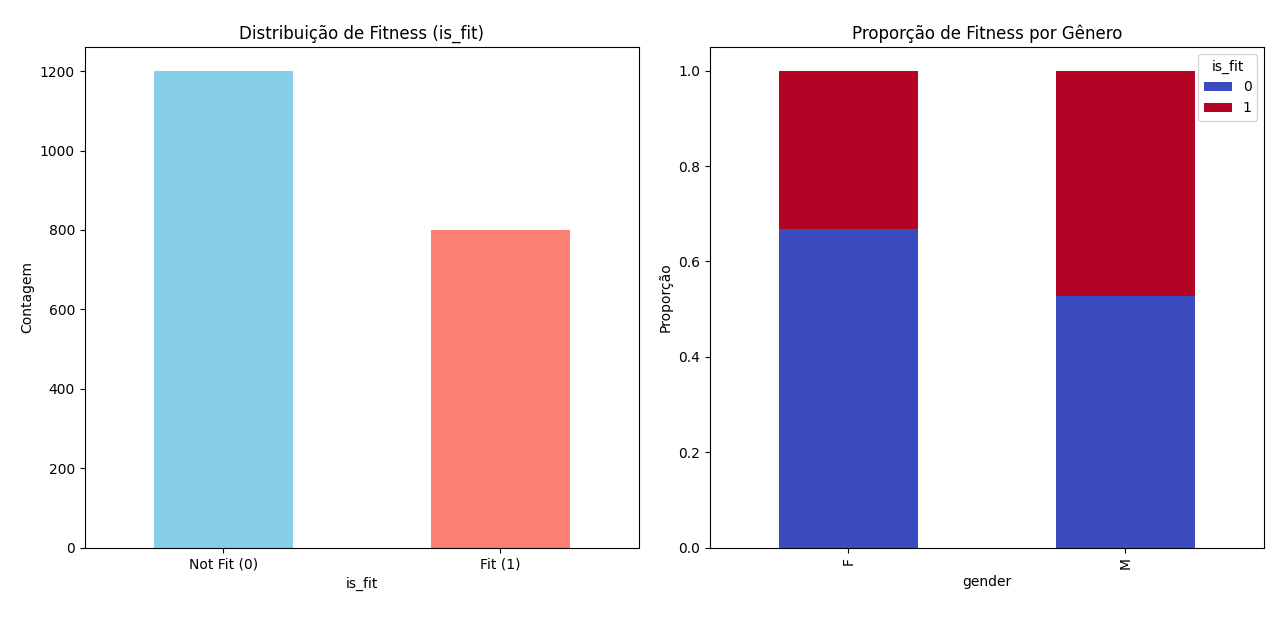
Descrição - Dataset: fitness_dataset.csv com atributos demográficos e de estilo de vida (age, weight_kg, activity_index, smokes, etc.). - Variável alvo: is_fit (1 = Fit, 0 = Not Fit). - Observação: leve desbalanceamento (mais Not Fit que Fit) e sobreposição entre classes em algumas projeções (PCA).
Visualizações e estatísticas (exemplos gerados pelo código): - Distribuição de is_fit (contagem/percentual). - Crosstab por gênero x is_fit. - Estatísticas descritivas (mean, std, min, max) para atributos numéricos.
2. Pré-processamento
Descrição - One-hot encoding apenas para colunas categóricas presentes. - Conversão de smokes para binário (0 = no, 1 = yes) antes do encoding, se aplicável. - Conversão forçada para numérico com pd.to_numeric(..., errors="coerce"). - Preenchimento conservador de NaN usando médias das colunas do treino (evita vazamento). - Padronização com StandardScaler (essencial para KNN).
Trecho de código (do script):
# one-hot + align
x_train = pd.get_dummies(x_train, drop_first=True)
x_test = pd.get_dummies(x_test, drop_first=True)
x_train, x_test = x_train.align(x_test, join="left", axis=1, fill_value=0)
# fillna com médias do treino e padronização
x_train = x_train.fillna(x_train.mean(numeric_only=True))
x_test = x_test.fillna(x_train.mean(numeric_only=True))
scaler = StandardScaler()
Xtr = scaler.fit_transform(x_train)
Xte = scaler.transform(x_test)
3. Divisão dos Dados
Descrição - Conjuntos já fornecidos pré-separados:
data/dataset-x-train.csv, data/dataset-x-test.csv, data/dataset-y-train.csv, data/dataset-y-test.csv.
Separação aproximada 80% treino / 20% teste (estratificada no preparo).
Observação: manter estratificação na divisão inicial e validar proporções de is_fit.
4. Treinamento do Modelo
Descrição - Algoritmo: KNeighborsClassifier. - Busca por hiperparâmetros com GridSearchCV (cv=5, n_jobs=-1) testando: - n_neighbors: 1..20 - weights: ["uniform","distance"] - p: [1,2]
Melhores parâmetros encontrados (execução atual): - k = 18
- weights = 'distance'
- p = 2 (Euclidiana)
Trecho de código (do script):
param_grid = {"n_neighbors": range(1,21), "weights": ["uniform","distance"], "p": [1,2]}
gs = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5, scoring="accuracy", n_jobs=-1)
gs.fit(Xtr, y_train)
best_params = gs.best_params_
5. Avaliação do Modelo
Descrição - Métricas calculadas no conjunto de teste: acurácia, precision, recall, f1 (classification_report) e matriz de confusão. - Curva de acurácia vs k por cross-val para justificar escolha de k. - Visualização da fronteira de decisão em PCA 2D para interpretação.
Resultados (execução atual) - Acurácia (teste): ~0.75
- Precision (macro): ~0.74
- Recall (macro): ~0.73
- F1 (macro): ~0.74
Matriz de confusão (valores observados) - 203 Not Fit corretamente classificados
- 37 Not Fit classificados como Fit
- 68 Fit classificados como Not Fit
- 92 Fit corretamente classificados
Acuracia.png— Curva Acurácia vs k

Matriz Fit or not.png— Matriz de Confusão

KNN.png— Fronteira de Decisão (PCA 2D)

Trecho de avaliação (do script):
y_pred = best_knn.predict(Xte)
print(classification_report(y_test, y_pred))
cm = confusion_matrix(y_test, y_pred)
6. Relatório Final
- Processo completo: carregamento → pré-processamento → padronização → GridSearch → avaliação → salvamento de figuras.
- Resultados: KNN com (k=18, weights='distance', p=2) apresenta acurácia ~75% e métricas macro ~0.74.
- Interpretação: modelo robusto para classe majoritária; erros concentrados onde há sobreposição de características entre classes.
- Melhorias propostas:
- Balanceamento (SMOTE / undersampling) e reavaliação por F1-macro.
- Feature engineering (IMC, horas sono, qualidade nutrição).
- Comparar com Random Forest, SVM e Logistic Regression.